详解数据服务共享发布 数据处理与存储支持服务
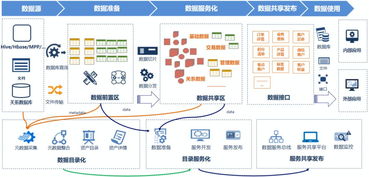
随着数字化时代的到来,数据已成为企业和组织的核心资产之一。数据服务共享发布作为数据管理的核心环节,涉及数据从采集到对外提供服务的全过程。其中,数据处理和存储支持服务是确保数据安全、高效和可靠共享的关键基础。本文将详细解析数据服务共享发布中的数据流程,并重点探讨数据处理与存储支持服务的具体内容、技术实现及其在实践中的应用价值。
一、数据服务共享发布概述
数据服务共享发布是指将组织内部的数据资源通过标准化的方式提供给内部或外部用户使用的过程。它通常包括数据采集、处理、存储、发布和访问等环节。共享发布的目标是提高数据的利用效率,支持业务决策和创新,同时确保数据的合规性和安全性。在数据驱动的环境中,共享发布能够促进跨部门协作、降低数据冗余,并推动数据价值的最大化。
二、数据处理支持服务
数据处理是数据服务共享发布中的核心步骤,涉及对原始数据的清洗、转换、集成和加工,以生成可用于共享的高质量数据。数据处理支持服务主要包括以下方面:
- 数据清洗与预处理:去除数据中的噪声、重复项和错误,确保数据的准确性和一致性。例如,使用自动化工具处理缺失值或异常值。
- 数据转换与集成:将不同来源的数据(如数据库、文件或API)转换为统一格式,并进行集成,以便后续分析。这通常涉及ETL(提取、转换、加载)流程。
- 数据加工与聚合:根据业务需求,对数据进行汇总、计算或建模,生成衍生指标或数据集。例如,通过机器学习算法生成预测模型。
- 实时处理与批处理:支持实时数据流处理(如Apache Kafka)和批量数据处理(如Hadoop),以满足不同场景下的时效性要求。
数据处理服务通常依赖于大数据平台、云计算工具(如AWS Glue或阿里云DataWorks)以及数据治理框架,确保数据在共享前具备高可用性和可理解性。
三、数据存储支持服务
数据存储是数据服务共享发布的基础设施,负责安全、高效地保存和管理数据。存储支持服务需考虑数据的类型、规模和访问频率,常见的存储方式包括:
- 关系型数据库:如MySQL或PostgreSQL,适用于结构化数据和高一致性场景。
- NoSQL数据库:如MongoDB或Cassandra,支持非结构化或半结构化数据的灵活存储。
- 数据湖与数据仓库:数据湖(如AWS S3)用于存储原始数据,支持多种数据格式;数据仓库(如Snowflake)则用于优化查询和分析。
- 分布式存储系统:如HDFS,适用于大规模数据存储,提供高可靠性和扩展性。
存储服务还需关注数据备份、恢复和容灾机制,以防止数据丢失。实施数据加密、访问控制和审计日志,确保数据在存储过程中的安全性与合规性。例如,通过角色-based访问控制(RBAC)限制数据访问权限。
四、数据处理与存储的整合应用
在实际应用中,数据处理与存储支持服务紧密集成,形成一个端到端的共享发布体系。例如,在智慧城市建设中,政府部门通过数据采集设备收集交通数据,经过ETL工具清洗和转换后,存储于云数据仓库中;再通过API接口对外发布,供企业和公众使用。这种整合不仅提升了数据处理的效率,还通过弹性存储方案降低了成本。结合AI和自动化工具,数据处理和存储可以动态调整,以适应不断变化的业务需求。
五、挑战与未来趋势
尽管数据处理和存储支持服务在数据共享发布中发挥着重要作用,但仍面临数据安全、隐私保护和性能优化等挑战。随着边缘计算、区块链和AI技术的发展,数据处理将更加智能化和实时化,存储服务则趋向于多云混合架构,以提升灵活性和可靠性。企业应持续投资于数据治理和技术创新,以充分释放数据共享的潜在价值。
数据处理和存储支持服务是数据服务共享发布不可或缺的组成部分。通过高效的数据处理和可靠的存储机制,组织能够构建安全、可扩展的数据共享平台,推动数字化转型和业务增长。这些服务将不断演进,为数据驱动型社会提供更强有力的支撑。
如若转载,请注明出处:http://www.xingfuqhd.com/product/4.html
更新时间:2026-06-19 18:30:11